Introduction
In this blog, I explain what transactions are in DBMS, why they are useful, how to write one, and then dive deep into the ACID properties. Transactions are essential whenever you’re updating, deleting, or interacting with shared data in a consistent and reliable way. I start by covering the basics of transactions—what they are, when and why to use them, and how to implement them. Then I explain the ACID properties:
- Atomicity
- Consistency
- Isolation (along with common read phenomena and how isolation levels help prevent them)
- Durability
Transactions
What??
A transaction in RDBMS, represents a bunch of queries run together in a unified way, it represents one unit of work done. So, lets say you write some UPDATE, SELECT, DELETE statements, now those are bunch of queries, what transaction does is that it binds all the queries and run together. It means, transactions have two states, success(committed), failure(rollback). When a transaction is COMMIT it means the queries ran by the user are successful and it being committed and the transaction ends. Now, there is another state called ROLLBACK, it means, undo what you (database) has done, and end the transaction. So, either a transaction fails or it succeeds.
Why??
What if you execute UPDATE and DELETE statements without using a transaction? If the database crashes or an error occurs midway, some changes might be applied while others aren’t — leading to inconsistent data. This is why transactions, and the ability to rollback, are critical. So, then either it wouldn’t have been set or deleted, and you return the value that hasn’t been deleted, which would be dangerous if you work on an application. For that transaction is used.
How??
I use postgresql, many of you use postgresql, so I wrote in postgresql syntax, its a very simple example, transactions can be complicated:
BEGIN;
SAVEPOINT query1;
--query 1
UPDATE bank_accounts SET balance = balance - 100.0 WHERE name = 'Ramesh';
--query 2
UPDATE bank_accounts SET balance = balance + 100.0 WHERE name = 'Tausiq';
ROLLBACK TO query1;
COMMIT;So, here you can see, there is BEGIN which marks the beginning of a transaction and there is COMMIT the end of the transaction. In between there are queries and, there is SAVEPOINT which saves a particular instance of database, if something wrong happens its being ROLLBACK to that SAVEPOINT. You might ask whats the use then, at the end of the day we are doing ROLLBACK, and the queries we wrote are gone to vain, so the above is just an example, you can programmatically write it in try-catch blocks or EXCEPTION in SQL.
When??
When you are doing critical queries and handling critical data, like UPDATE, DELETE, even on rows or on the table. Secondly, when a query or transaction waits for another transaction to complete, if that second one is not a transaction, and if you wait for that query to run and if the db crashes you won’t get that data. Or, you are writing another transaction.
So, thats all about transactions in db. Lets move into ACID.
ACID Properties
What??
ACID stands for Atomicity, Consistency, Isolation and Durability. Those are four properties of database transactions. If we don’t follow them, we have lost updates, data corruption, invalid states or unpredictability of data. So, I wrote about them in detail below. First, lets start with Atomicity, then Isolation, Consistency, Durability.
Atomicity
Atomicity defines that a transactions should have only two stated, either it should be committed or it should be reverted (ROLLBACK). There shouldn’t be anything in-between, which will lead to data inconsistency or data corruption. So, we have seen above example that, we are reverting the changes, but thats just a simple example, so while handling transactions programmatically, we should write try-catch or exception to catch if some error happens and revert the query to the initial state or saved state, else commit the transaction. Thats simple, thats it.
Isolation
I wrote Isolation before Consistency because, Isolation will lead to Consistency and part of Consistency. So, Isolation says that during an inflight transaction can we read/write other transactions or not, and if we do how it will affect us and affect them. So, we should isolate transactions, so that it shouldn’t affect other transactions, or apply some solutions to do so. If we fail to do so it raises “Read Phenomena”. Read Phenomena is of four types:
- Dirty Reads
- Non-repeatable Reads
- Phantom Reads
- Lost updates
Dirty Reads
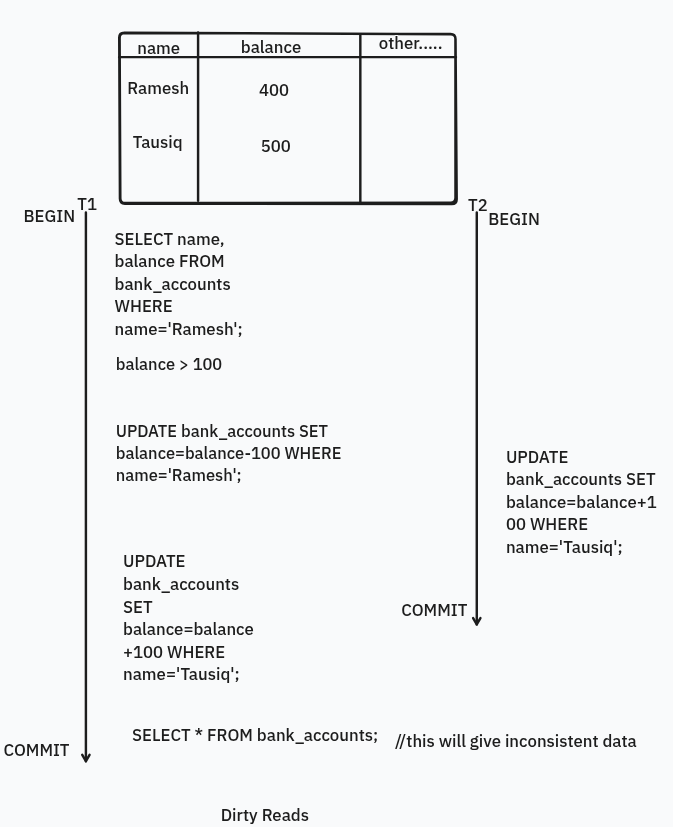
Assume there are two transactions, and we are performing at same time. So, in first transaction you read some data and and then perform an update on itself, on the other hand second transaction also updates and then the first transaction reads the update made by the second transaction, which it shouldn’t as the data hasn’t been committed. So, it should give dirty read to your transaction and you should isolate your transaction.
For e.g.: Above, you can see T1 reads and checks if balance > 100 or not for Ramesh, and updates the Ramesh’s balance, while T2 updates Tausiq’s balance, and same does T1 and then when T1 tries to read balance it gives incorrect data
Non-repeatable reads
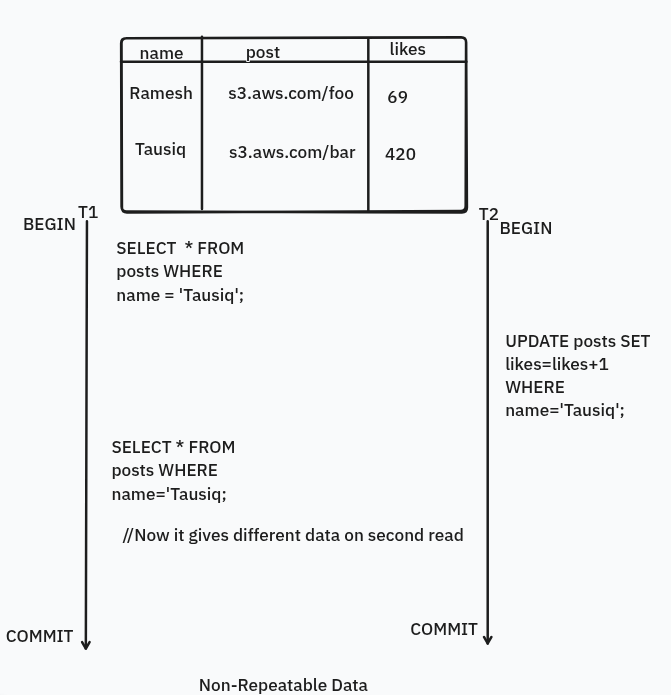
Non-repeatable reads are those reads where you read a data in the transaction, then after some time I read the same data but gets different result because of the changes made by other transactions whether they are committed or uncommitted. So, it leads to data inconsistency. Sometimes, we are okay with this type of things, like in the above case, sometimes we are don’t like bank transactions or any critical updates.
Example: Above you can see there are two transactions T1 and T2, so T1 reads the data from the db, then T2 changes the data in db, then again T1 reads and gets different data
Phantom Reads
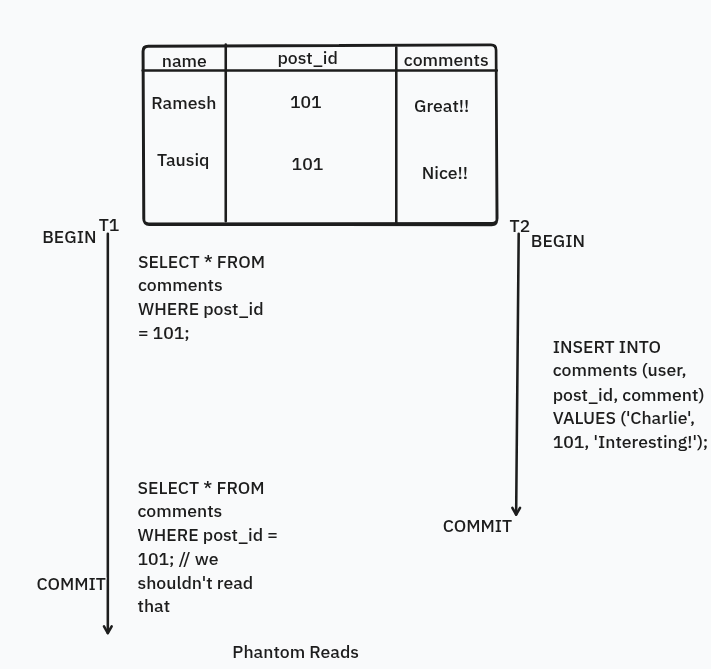
Phantom Reads are those reads that needs to be avoid, means if you have transaction and you read stuff, and another transaction happens and data is being inserted into the db, which you can’t prevent and you read again it would give different results, so you should avoid that.
Example: In the above example, there are two transactions and T1 reads data at first, then T2 inserts datum into the db and then T1 again reads which gives it wrong results.
Lost Updates
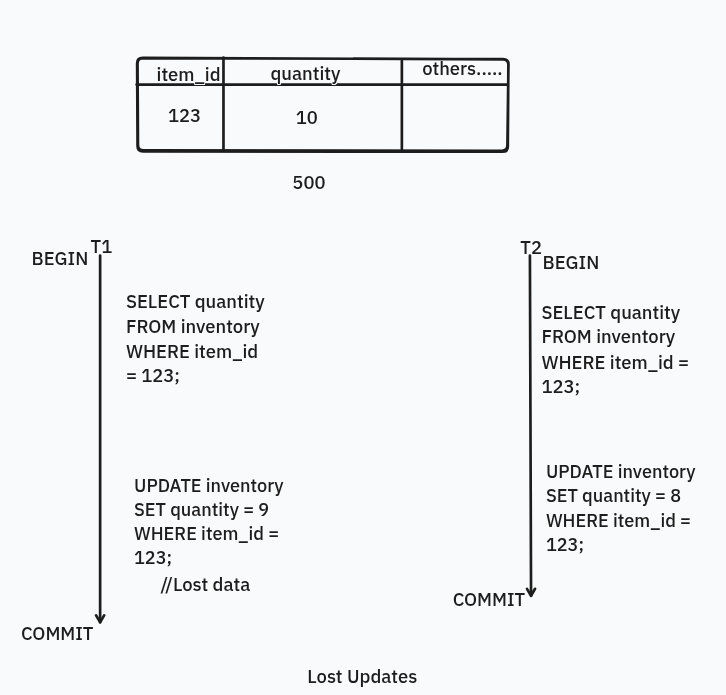
Lost Updates are the phenomenon where you update or write data into the db using a transaction and another transaction comes in write into the database its own data and commits, so when you read that data or that data that you have written is being lost.
Example: Above you can see there are two transactions T1 and T2, and at the same time both read and write the data and the data written by T1 is being lost.
Solutions to Isolation
So far we have seen, there are four read phenomena which affects Isolation property of a db transaction. So, to solve those Isolation Levels are introduced, there are four isolation levels:
- Read Uncommitted
- Read Committed
- Repeatable Read
- Serializable Features of those levels:
- Those levels are ordered in increasing of isolation level, so Read Uncommitted has 0 isolation, or the transaction hasn’t been isolated at all, so nothing solves, while the last one Serializable is at the highest.
- Those levels are ordered in decreasing order of performance, so first Read Uncommitted has the most performance, while the last has the least.
Read Uncommitted
This is the lowest isolation level, where one transaction can read data that another transaction has written but not yet committed. This means dirty reads are possible data might be rolled back later, making what was read invalid or inconsistent. It offers the highest performance because there’s virtually no locking, but it’s extremely unsafe for critical systems.
Read Committed
At this level, a transaction can only read data that has been committed by other transactions. This prevents dirty reads. However, it still allows non-repeatable reads if a transaction reads the same data twice, and another transaction modifies and commits in between, the second read may return different results. Read Committed is the default isolation level in many databases like PostgreSQL and strikes a good balance between consistency and performance in many applications.
Repeatable Reads
This level ensures that if a transaction reads a row once, it will get the same data every time it reads that row again even if other transactions update and commit changes to it in between. This prevents both dirty reads and non-repeatable reads. However, it still allows phantom reads if a transaction again executes a query that returns a set of rows (like SELECT * FROM ... WHERE), it might see new rows inserted by other transactions that weren’t visible before. This level uses stricter locks or multiversion concurrency control to ensure repeatable reads.
Serializable Reads
This is the highest level of isolation. It ensures complete isolation between transactions, making them behave as if they were executed one after the other (serially), even if they run concurrently. This prevents all read phenomena: dirty reads, non-repeatable reads, phantom reads, and lost updates. It’s the safest but also the most expensive in terms of performance, as it may involve locking large portions of data or rejecting conflicting transactions to maintain serializability. This level is ideal for critical systems requiring strict correctness.
Consistency
Consistency means after operations in transactions being performed, the state should remain valid or the data should be consistent. There are two types in it:
- Consistency in Data
- Consistency in Reads
Consistency in Data
It defines the correctness and validity of data in the database. After transactions being committed the data should remain consistent. It can be achieved in four ways:
- User defined : Consistency can be largely achieved by the user through constraints and rules. These include data types,
NOT NULLconstraints,CHECKconstraints, unique constraints, and business logic enforced via application code or database triggers. If a transaction violates any of these rules, the database must reject it, preserving consistency. - Referential Integrity: Referential integrity is a key aspect of consistency, especially in relational databases. It ensures that relationships between tables remain valid. For instance, if a table
ordershas a foreign key referencing auserstable, then everyuser_idinordersmust correspond to an actual user in theuserstable. If someone tries to insert an order with a non-existentuser_id, the transaction should fail, thus preserving consistency. - Consistency via Atomicity and Isolation: Atomicity and Isolation are both critical in maintaining consistency. Atomicity ensures that a transaction is all-or-nothing, either all changes are applied or none are. This prevents partial updates that could corrupt data. Isolation ensures that concurrent transactions don’t interfere with each other in ways that could lead to inconsistent or invalid data states, such as two users withdrawing from the same account simultaneously and both seeing the same initial balance.
Consistency in Reads
It defines when you update data in database and after that update happens can you read that same data from the database, the answer is both yes and no, and this is a problem that both RDBMS and No-SQL suffer because of scaling, if we horizontally scale data, or add more servers, something known as sharding then the Read becomes inconsistent because there are distributed servers and data may be inconsistent, resembles kind of CAP theorem, but I will write about it later on. If data is in one server, then if we update, we can get consistent data, but when we have different servers we might not. Now solution for that is Eventual Consistency, that means eventually every data will be consistent.
Durability
This is the final property of a transaction. It says if a transaction is being committed successfully, it should be stored in a non-volatile (secondary or hard disk) storage. And the changes are permanently saved into that storage, even if the system fails without losing any data. In-memory database like Redis, doesn’t follow this property because its stored in-memory and used for caching, its obvious.
Thats it. Thats all about ACID properties in RDBMS. Thank you for reading, if you want to give any suggestions, or this blog needs improvements, please comment below, or dm me at: x.com/tausiqtweets
Thanks to https://www.youtube.com/watch?v=pomxJOFVcQs (Hussein Nasser), I learnt from him and some blogs and wrote this article.
If you enjoy this blog and want to support me, you can do at: https://buymeacoffee.com/tausiqsamantaray
Good day, see you next time
…